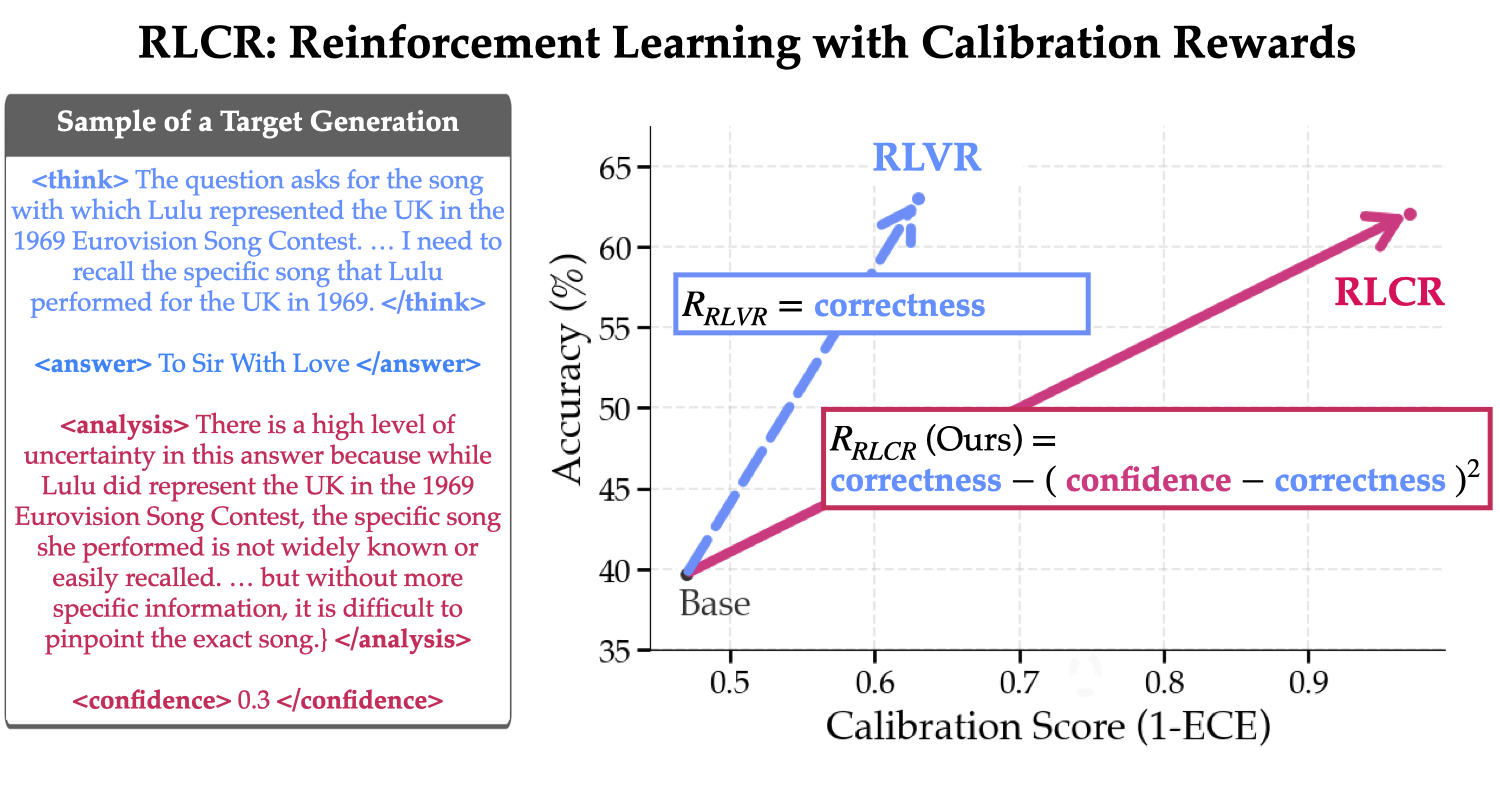

Recent advances in reasoning training — particularly RL with verifiable rewards (RLVR) — have improved the accuracy of large language models (LLMs). These approaches optimize for correctness, encouraging models to output the right answer when possible.
However, these same methods tend to produce overconfident models that are more prone to hallucination. Because the reward signal focuses solely on final answer correctness, models are incentivized to guess — even when they are uncertain. This is especially problematic in high-stakes settings like healthcare and law, where confident errors can be harmful or even dangerous.
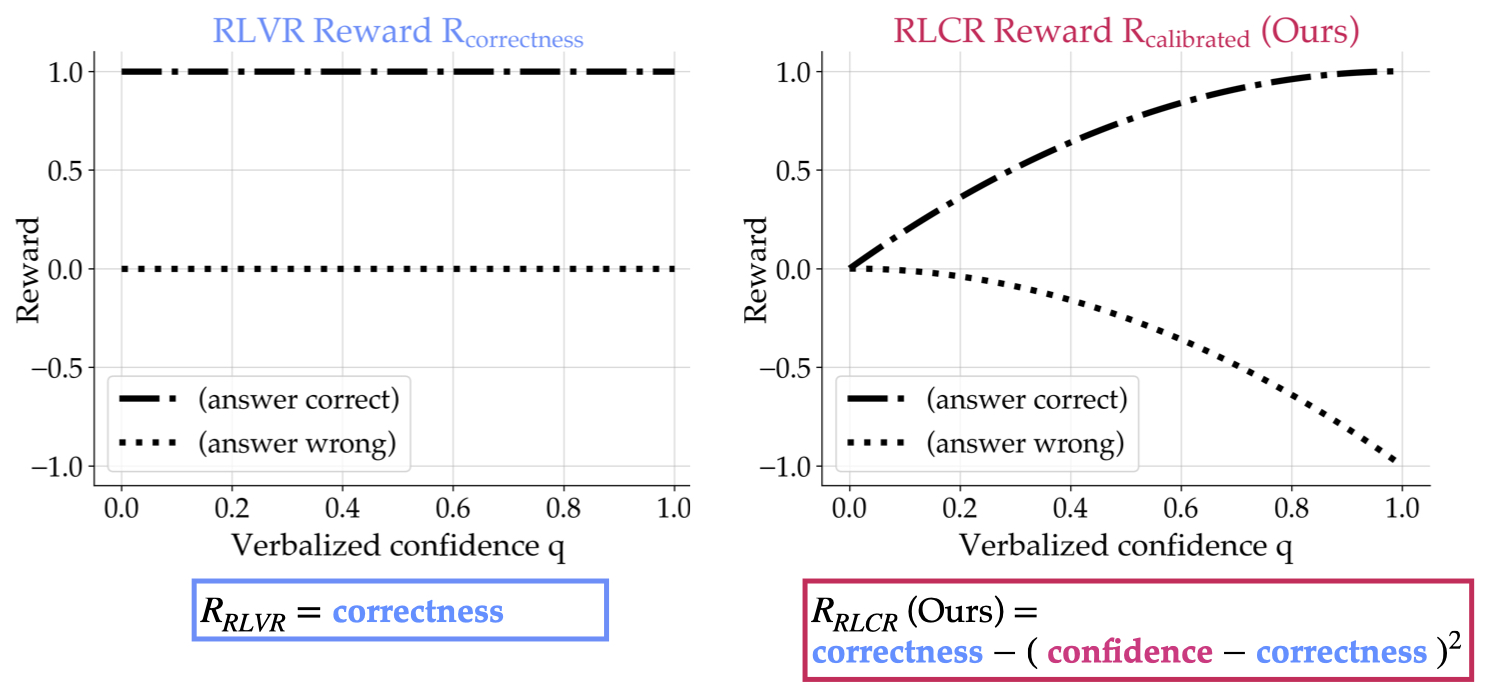
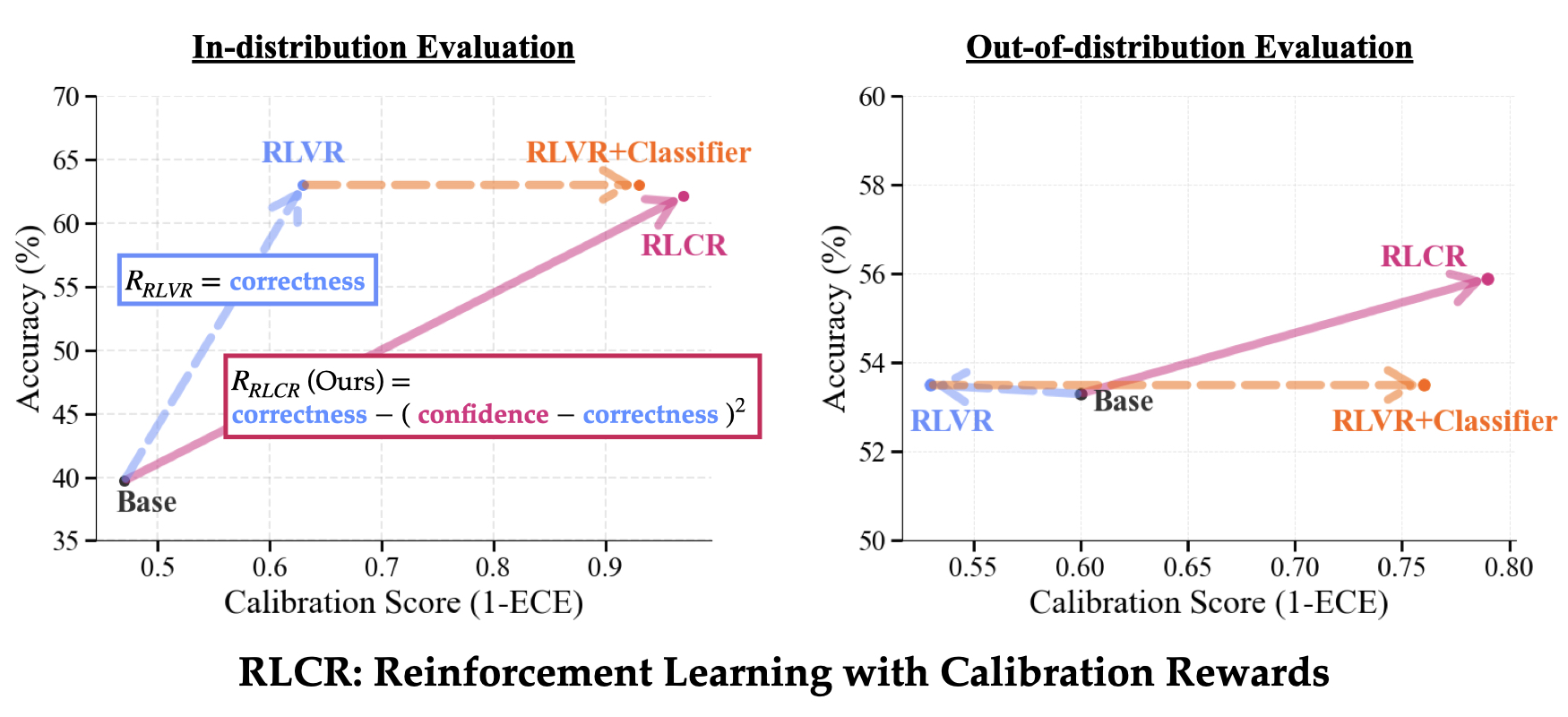
RLCR addresses this gap. We introduce a reinforcement learning framework that trains models to reason about their own uncertainty — rewarding not just accuracy, but also calibrated confidence.
Instead of encouraging blind certainty, RLCR incentivizes models to reflect, evaluate their own outputs, and communicate uncertainty when appropriate. The result is a model that performs better (higher accuracy ✅) and knows when it's likely to be wrong (better calibration 🎯).
In domains where trust, safety, and interpretability matter, this dual optimization — getting the right answer, and knowing when you might not — makes all the difference.